

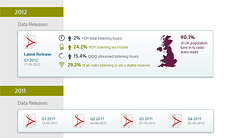


Data processing
Scanning
All questionnaires and diaries are processed using optical scanning technology. Following this, the scanned data undergoes a series of checking procedures including a computer program designed to test quality by checking for any logical inconsistencies. Diaries not meeting stringent criteria are double-checked by hand, the interviewer and/or respondent may be re-contacted and if any doubt remains over the veracity of the diary data, it is excluded from the analysis.
Write In
"Write-in" listening, where a respondent writes in the name of a station for which there is no label, is attributed to "BBC Local" or "Local Commercial" as applicable. If the station cannot be identified it is coded as "Other Listening".
Editing
Listening records for Digital only services are cross referenced against platform ownership and access claims collected from the Recruitment Questionnaire.
Weighting and Grossing Up
Once all the data has been collected, weighting procedures are then implemented to ensure that the population estimate on which the station’s audience is based is representative of the entire TSA's population.
The weighting procedure is in two stages:
- Pre-weights are applied to correct for disproportionate sampling at the segment level.
- Ethnic Origin pre-weights are applied to correct imbalances in the achieved sample according to 'white' and 'ethnic category' groups.
- Final Rim weights reflect demographic weighting to correct the profile of the achieved sample in the total universe and each TSA in terms of sex, age, social grade and household size:
Rim 1 (15-24, 25-34, 35-44, 45-54, 55-64, 65+) by (Men, Women) by (ABC1, C2DE).
Rim 2 (Adults in h/h/ size 1, 2+).
Rim 3 (Children 10-14) by (Male, Female).
Rim weighting is a series of iterations of single-variable cell weighting. You begin with the first variable and you weight the sample by each cell within this variable. The weighted distribution will match the universe on this variable. Then you move to the second variable and you obtain the weighted distribution by each cell within this variable but it may no longer match the universe on the previous variable. This process is repeated for the rest of the variables, and started again at the first variable, and so on. After a number of iterations, the weighted sample will converge towards the universe on all the variables.
Dependent upon TSA sample size and the nature of overlays with other TSAs, these rims will be collapsed to varying degrees in different TSAs. The full specification always applies to the total universe. The Social Grade and Household Size targets are derived from the NRS.
Total universe targets are also applied to control ethnicity for White, Asian, Black and other ethnic category backgrounds in London and for the entire UK. Control is also applied to correct for the oversampling in segments identified as ethnic.
The final rim weights also control representation of Welsh language speakers (in Wales only). These targets are derived from an average of previous RAJAR reported populations of Welsh Understanding / Fluency.
The RAJAR frequencies of reporting are monthly, quarterly, 6-monthly and yearly. There is a different set of weights for each of these frequencies, and only results based on the same frequency of reporting can be compared. For example, it is not possible to compare quarterly results with monthly results by simply dividing quarterly results by 3, as they are completely different sets of data with different weightings applied to them.
All targets are updated annually with June's data release.
Predicted Cumulative Audience
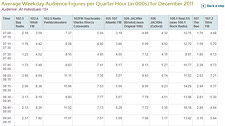
Predicted cumulative audiences for 2 to 13 week periods are shown on table 10 for each service. These audience figures are calculated by a probability model which uses data for reach build within the one week period covered by the diaries to predict reach build over an extended period beyond that week. This model uses a Negative Binomial Distribution.
15 Alfred Place
London WC1E 7EB
Tel +44 (0)20 7395 0630